
В те времена, когда о нейросетях знали совсем немногие, разработчики Google уже начинали первые, весьма робкие, работы по улучшению поиска технологиями машинного обучения.
До 2013 года поисковое продвижение в Гугле было довольно простым, а сам алгоритм ранжирование был, мягко говоря, не мудреным. Можно даже сказать примитивным.
Колибри (2013)
Итак, в 2013 году Google внедрил Колибри (англ. Hummingbird). Поисковик никогда не раскрывал подробностей работы, но небезызвестный Мэтт Каттс заявил:
Колибри — переписанный алгоритм основного поиска. Просто для того, чтобы лучше сопоставлять запросы пользователей с документами, особенно для запросов на естественном языке. Запросы становятся длиннее, в них больше слов, и иногда эти слова имеют значение, а иногда нет.
Таким образом, Hummingbird – это не просто дополнительный слой, как, например, фильтры Пингвин и Панда, а целиком переработанный основной алгоритм поиска.

Что мы знаем об этом алгоритме
В основе алгоритма лежит граф связности понятий, аналогичный Knowledge Graph. Не добавляющие семантической полноты слова исключаются, а остальные приводятся к смысловым единицам и кодируются.
Возьмем исходную фразу:
Очень даже возможно; его верность – все равно что фасон его шляп: меняется с каждой новой болванкой
После очистки от незначащих слов и знаков препинания она может выглядеть так:
возможно верность фасон шляпа меняется новая болванка
А после кодирования так:
sfg3f#a uif1jrg7 hj6bdn k_a346fnj vcb@4jgf gh56mgm aa45kgjk
Семантической единицей при этом может быть как отдельное слово так и словосочетание.
Затем алгоритм представляет текст как связи сущностей, которые упрощенно можно изобразить графом вроде этого:
Так определяется какие семантические единицы должны быть в тексте. Конечно, связность между ними рассчитывается не на основе 1-2 текстов. Ведь роботы Google постоянно сканируют сотни миллионов страниц, медленно но верно дообучая алгоритм.
Это довольно довольно общее описание нейросетевой языковой модели, которым сейчас никого не удивить, а подробностей об алгоритме поисковая система не раскрывает.
Зачем внедрили Hummingbird?
В Google заявили, что преследовали следующие основные цели:
- Улучшение общего качества поиска, путем снижения влияние ссылочных факторов и спама ключевыми словами;
- Улучшение результатов по запросам на естественном языке. Это было необходимо в связи с ростом количества голосовых запросов с мобильных устройств. Эти запросы часто содержат много бесполезной для поискового алгоритма “воды”;
- Борьба с поисковым спамом (дорвеями) и бесполезными материалами, оптимизированными под запросы “длинного хвоста” – это редкие ключевые фразы, обычно состоящие из большого количества слов.
Последствия для поискового продвижения в Рунете
Инженеры Гугл заявили об алгоритме:
«Он повлиял на 90% запросов, но только в небольшой степени, мы развернули его в течение месяца, а люди даже не заметили этого… это не то, о чем вам нужно беспокоиться. Он не потрясет ваш мир…»
Отчасти, это можно объяснить тем что алгоритм был недообучен, и ему требовалось время.
Поскольку Колибри разрабатывался, в первую очередь, для англоязычных запросов, на Рунет алгоритм оказал меньшее влияние. Однако, кое-что все-так произошло.
Часто стало нецелесообразно создавать посадочные страницы под упомянутые выше длиннохвостовые запросы. И это задело не только генерированный контент и спамные сайты.
По некоторым запросам в поисковой выдаче наблюдалось “мигание“, когда оптимизированная под редкий запрос статья периодически то попадала в ТОП-10 на время, то вылетала из него в далекие глубины.
В таких условиях даже упоминался термин “консервация выдачи“, то есть длительное отсутствие динамики в ТОП по запросу и невозможности в него попасть. Впрочем, это коснулось далеко не всех тематик, вероятно, из-за сложности понимания Google русского языка.
RankBrain (2015)
Развитие поиска продолжилось в 2015 году с релизом RankBrain, первого поискового алгоритма Google, работающего на основе глубокого обучения. Дополняя Колибри, новый алгоритм помог поиску лучше соотносить слова и понятия.

Так, патент Гугла US9104750B1 объясняет, что в основе алгоритма лежит определение концепции запроса и замещение синонимами всего запроса или отдельных его слов. Вот пример:
Например, вы ищете «как называется потребитель на самом высоком уровне пищевой цепи».
Алгоритм, видя эти слова на разных страницах, понимает, что концепция пищевой цепи относится к животным, а не к людям-потребителям.
Сопоставляя слова запроса с соответствующими понятиями, RankBrain понимает, что вы ищете то, что обычно называют «высшим хищником».
вице-президент Google Поиска Pandu Nayak
Среди прочего, RankBrain нацелен на решение следующих задач:
- Обработка слов-омонимов;
- Лучшее понимание, когда нужно учитывать такие части речи как союзы, предлоги и частицы, а когда нет;
- Персонализация поисковой выдачи на основе истории поисков, местоположения пользователя, а также актуальных трендов;
- Учет поведения пользователей, особенно клик по ссылке в поисковой выдаче;
Кроме того, по статистике Google, около 15% всех запросов являются уникальными. То есть, их никогда раньше не вводили (возможно, и позже никогда не введут). RankBrain улучшает результаты по этим фразам.
В целом, Hummingbird и RankBrain похожи, однако, первый больше ориентирован на понимание интента (намерения) лежащего в основе запроса, а второй – его значения и синонимов. Эта связка считается оптимизаторами важной частью текущего поискового движка Google.
BERT (2019)
BERT – акроним от Bidirectional Encoder Representations from Transformers, что можно перевести как “двунаправленный кодировщик представлений на основе трансформеров“. Он не является поисковым алгоритмом как таковой, а доступ к экспериментам с ним может получить любой, при помощи GitHub.
Итак, BERT – нейросетевой алгоритм для обработки естественного языка (Natural Language Processing), применяется для решения различных задач по обработке текста, например:
- классификация и выявление тематик,
- определение тональности и эмоциональной окраски,
- перефразирование создание выжимок из текста.
BERT обучается без учителя на больших корпусах данных, таких как словари и крупные тезаурусы. В основе обучения лежит токенизация текста в соответствии со словарем. Затем часть токенов заменяется на маски.
Например, предложение “Как SEO-специалист, я оптимизирую сайты” может быть заменено на “Как [МАСКА]-специалист, я [МАСКА] сайты“. Затем модель должна составить первоначальное предложение. В случае простых примеров вариантов может быть довольно много, однако в текстах большого объема вариативность резко снижается и выводы нейросети намного однозначнее.
BERT от Google
В 2019 году Google выложил свою реализацию нейросети (названную ALBERT) из несколько предобученных многоязыковых моделей BERT со множеством слоев, узлов, выходов и параметров. В частности модель BERT-Base, поддерживает 104 языка, состоит из 12 слоев, 768 узлов, 12 выходов и 110M параметров, а ее словарь составляет 30522 слова. В том же году было заявлено что поисковая система Гугла будет использовать нейросеть для интерпретации поисковых запросов и ранжирования.
BERT понимает, как сочетание слов выражает сложную идею. BERT понимает последовательность слов и то, как они связаны друг с другом, поэтому гарантирует, что мы не пропустим важные слова из вашего запроса — какими бы маленькими они ни были.
вице-президент Google Поиска Pandu Nayak
Заявленное Google ключевое отличие от RankBrain в том, что BERT не просто способен искать по синонимам фраз и слов, но по-настоящему понимает что ищет пользователь. Что, конечно же, является преувеличением.
Свои реализации модели есть также у Facebook (RoBERT) и Microsoft (MT-DNN).
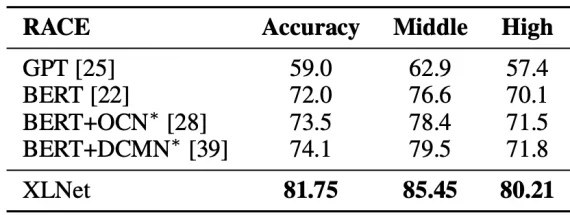
Стоит заметить, что уже в 2019 году BERT не был наилучшей (на основе теста RACE – Reading Comprehension From Examinations), нейросетевой моделью для обработки языка. Уже тогда ей была другая модель – XLNet, показавшая лучшие баллы на датесетах среднего и большого объемах.
Возможно, поэтому инженеры Гугла поторопились с новыми разработками.
MUM – будущее поиска Google
В мае 2022 года Google анонсировал появление принципиально нового нейросетевого ранжирующего алгоритма, Multitask Unified Model или MUM. Алгоритм обучен на 75 языках и способен решать множество задач.
В 1000 раз мощнее, чем BERT, MUM способен как понимать, так и генерировать контент […] MUM также является мультимодальным, то есть он может понимать информацию в нескольких модальностях, таких как текст, изображения и многие другие в будущем.
Алгоритм пока не развернут, по крайней мере настолько, чтобы его влияние было заметно. Но вот что обещает на Гугл в будущем:
- Максимально комплексные ответы, всесторонне и в деталях раскрывающие тему;
- Блок Thing To Know – подобранные нейросетью дополнительные запросы. Похоже на текущую механику похожих запросов, но гораздо более полезную;
- Zoom Topic – удобная работа с базой знаний, позволяющая как изучать темы поверхностно, так и углубляться в любые подробности.
- Полноценный Google Lens. Поиск с помощью запроса, но на основе изображения.
Так, например, вы сможете сфотографировать рубашку, и попросить поисковик найти носки с тем же принтом.

В целом, ожидается что MUM оставит в прошлом классическую выдачу с ТОП-10 и съем позиций. Колдунщики и ссылки будут постоянно учитывать историю поиска, предпочтительный формат контента, намерения и интересы каждого конкретного пользователя и каждая выдача будет уникальна.
Но как все эти алгоритмы работают вместе?
На самом деле, мы этого не знаем. Нам остается только доверять словам уже цитируемого выше вице-президента Google Search:
Когда мы разрабатываем новые системы искусственного интеллекта, наши устаревшие алгоритмы и системы не просто откладываются на полку.
Фактически, Поиск работает на сотнях алгоритмов и моделей машинного обучения, и мы можем улучшить его, когда наши системы — новые и старые — могут хорошо работать вместе.
Каждый алгоритм и модель играют особую роль, и они срабатывают в разное время и в разных комбинациях, чтобы помочь получить наиболее полезные результаты.